PrivateTrace-Backend
2023年华南理工大学攀登计划,隐私保护的敏感人群轨迹接触追溯系统后端。使用SpringBoot框架和百度地图API开发,自定义B+树索引模拟数据库。
项目地址

一、选题背景
云外包时空数据查询服务面临数据泄露、数据推断等安全威胁。时空数据包含用户行动轨迹、生活习惯等个人敏感数据,时空数据泄露与滥用将对个人生活造成极大困扰,对社会造成严重负面影响,阻碍时空数据要素资源的开发利用。
目前,基于隐私计算等相关技术可以达到“数据可用不可见”的目标。但是,由于这种技术采用同态加密、计算操作在密文上完成,计算的复杂度高、时间长的缺点。这就需要我们改进传统的比较算法O(n²),从数据结构等角度出发,设计出减小关键算子计算量的算法。
为了应对这些挑战,本项目以设计安全且高效的隐私保护时空接触追溯系统为基本目标。一方面,我们使用多种基本数据结构如双向链表,红黑树等设计高抽象的高级数据结构,另一方面基于设计的数据结构,完成高效的密态轨迹比较算法,在保证不泄露隐私数据的前提下减少算法额外开销,实现面向密态时空数据的精准查询和追溯,最终形成安全且高效的隐私保护时空接触追溯系统。
二、方案论证(设计理念)
2.1 B+树

对于不同用户的所有不同轨迹,我们首先进行一次时间范围上的裁剪。即如果两段轨迹在时间上没有相交,那么系统将不会对他们进行位置信息的比较,从而减小计算量。
具体的说,我们在B+树的节点Node中使用List记录具体的key值、子节点、轨迹等信息,使用B+树记录完整的所有用户的轨迹信息。其中,B+树节点的key值为加密轨迹中记录的轨迹起始时间(BeginTime),叶子节点行中各轨迹按起始时间升序排列。由于不同轨迹的起始时间可能相同,因此我们允许B+树内部节点中拥有相同的key值。树的结构图如图所示。
2.2 交集
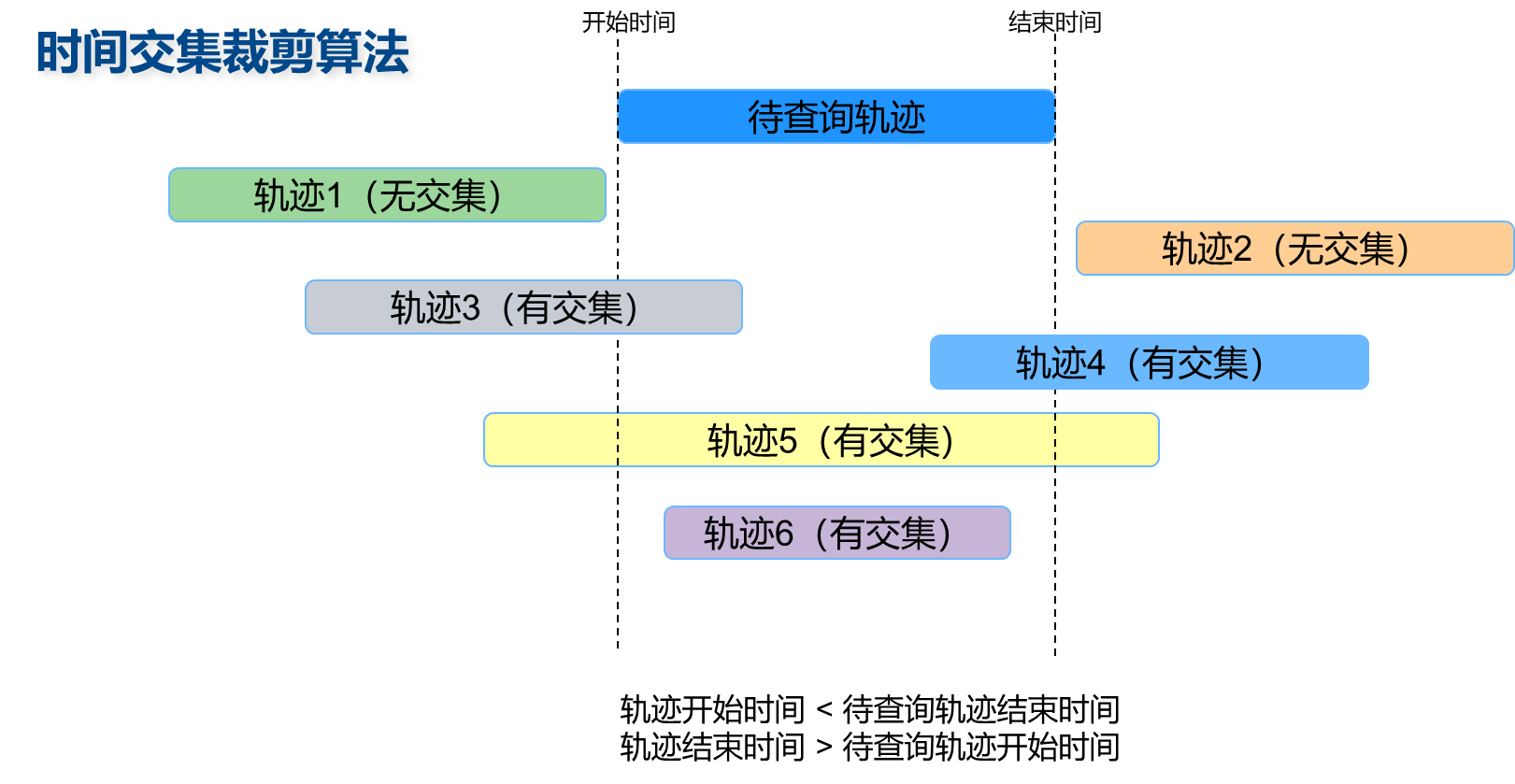
本算法为整棵树中的核心算法,系统通过本算法完成时间裁剪,减少后续密文时空查询的计算量,以减少算法运行时间。对于一个用户的时空轨迹,有如图所示四种情况,即1.轨迹开始时间在待查询轨迹范围时间中和2.轨迹开始时间<待查询轨迹开始时间且轨迹结束时间>待查询轨迹开始时间两类。
在算法的设计时,最初并没有关注到第二类情况,欲采用简单的开始时间进行范围查询,从而出现时间裁剪遗漏的情况。后经仔细思考,设计了新的时间裁剪算法,具体算法如下。
现已知一个用户的轨迹信息,通过时间相交比较算法可以找到树中与该轨迹有时间交集的所有轨迹。用户轨迹的起始时间beginTime,结束时间为endTime,树中存储的最大时间跨度maxTimeLength,则算法的起始查询时间searchTime为:
searchTime = beginTime – maxTimeLength
设置起始查询时间的意义是,减少对叶子节点的查询次数,限定算法在合理的范围查找有时间交集的轨迹。
得到起始查询时间后,算法将快速在树的叶子行中找到第一段起始时间大于searchTime的轨迹,然后从本节点开始遍历,直至节点所存储轨迹的开始时间大于endTime。遍历过程中,若节点中轨迹的结束时间大于beginTime,则认为两端轨迹在时间上相交。
2.3 轨迹断点处理

2.4 系统架构

2.5 系统流程

